병렬처리란
여러 개의 프로세서를 통해 하나의 프로그램을 처리하는 방법에 대해 알아봅니다.
목표
- 병렬 처리에 대해 알아봅니다.
- HPC와 성능 결정 요인을 학습합니다.
- 병렬 처리에 사용되는 프로토콜을 학습합니다.
HPC - 성능 결정 요인
크게는 헤르츠(Hertz)와 CPI(Cycles Per Instruction) 두가지 요인으로 결정됩니다.
- Hertsz - 기계 주기 (Machine cycle)
- 프로세서의 동작 주기
- CPU의 클럭 ( CPU 진동, 주파수)
| Clock Frequency | 1초 기준 사이클의 수 | 1사이클 기준 걸리는 시간 |
|---|---|---|
| 1 Hz | 1초에 1개의 사이클을 수행 | 1개의 사이클을 수행하는데 걸리는 시간은 1초 |
| 100 hz | 1초에 100개의 사이클을 수행 | 1개의 사이클을 수행하는데 걸리는 시간은 1/100(10ms) |
1 | |
[CPU Excution Time] = [Instruction Count] X [CPI] X [Clock Cycle Time]
- CPU 실행시간 = 명령어 갯수 * 명령어당 소요되는 사이클수 * 클럭당 소요되는 사이클 시간
파이프라이닝 기법
Instruction pipeline 은 명령어를 읽어 순차적으로 실행하는 프로세서에 적용되는 기술입니다. 한 번에 하나의 명령어만 실행하는 것이 아닌 하나의 명령어가 실행되는 도중에 다른 명령어 실행을 시작하는 식으로 동시에 여러 개의 명령어를 실행하는 기법입니다.
- 파이프라인의 궁극적인 목표는 “처리량”(throughtput)을 늘리는데 있습니다.
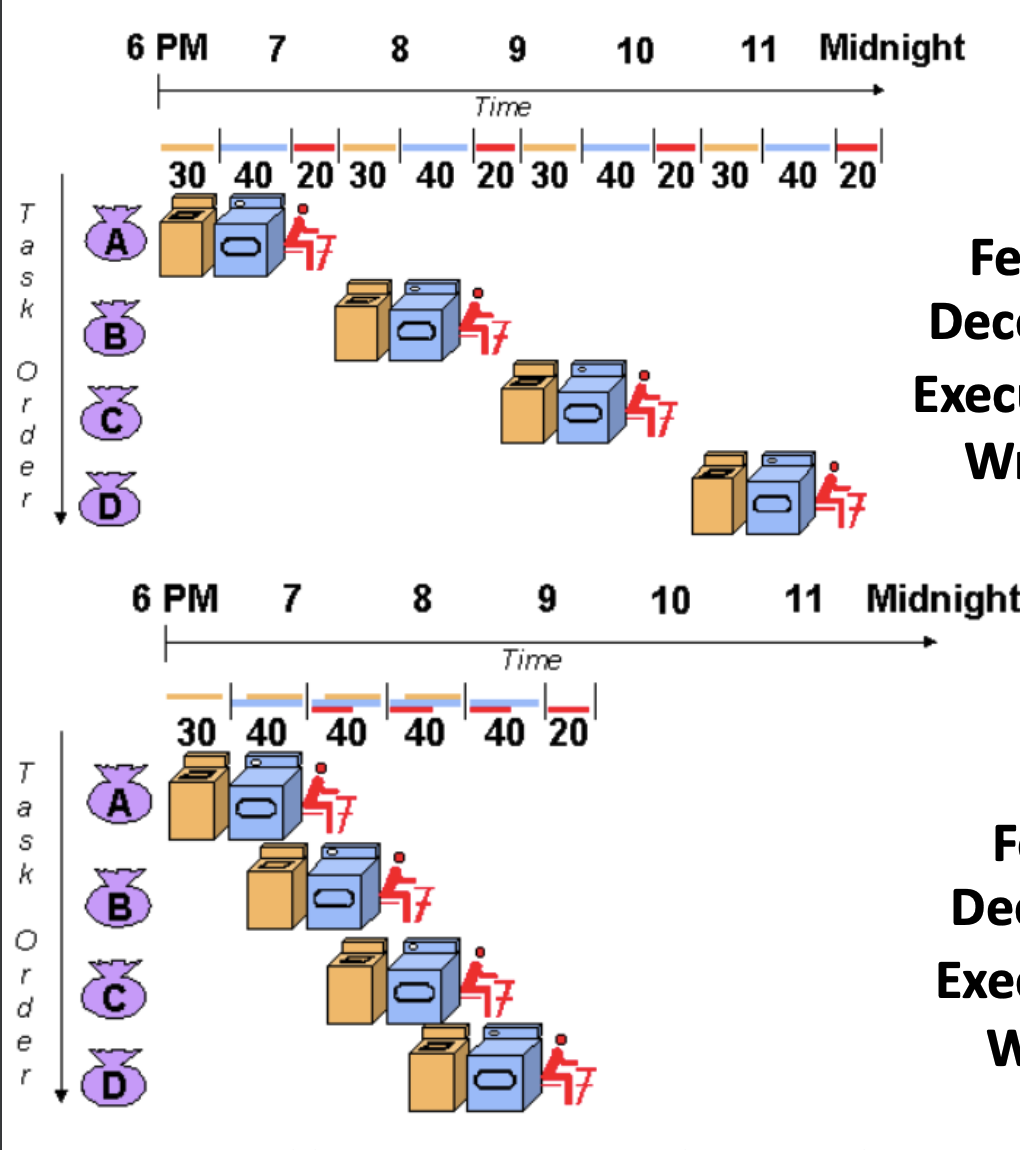
4번의 세탁과정에 대한 그림입니다. 위는 순차적으로 진행된 세탁 과정입니다.
X축은 각 Task 당 걸리는 시간축으로 클럭수라고 봐주시면 되겠습니다, Y축은 작업 명령 (Task Order)로 이루어져 있습니다.
위의 그림은 “세탁-건조-정리” 순으로 각 작업이 독립적으로 실행됩니다.
- 작업이 끝나는 데 걸리는 시간은 12시간 (12클럭)이 소요됩니다.
아래 그림은 각 작업이 진행되는 동안 다른 작업을 동시에 진행할 수 있습니다.
- 작업이 끝나는 데 걸리는 시간은 6시간(6클럭)이 소요됩니다.
Non - Pipelined
Pipelined
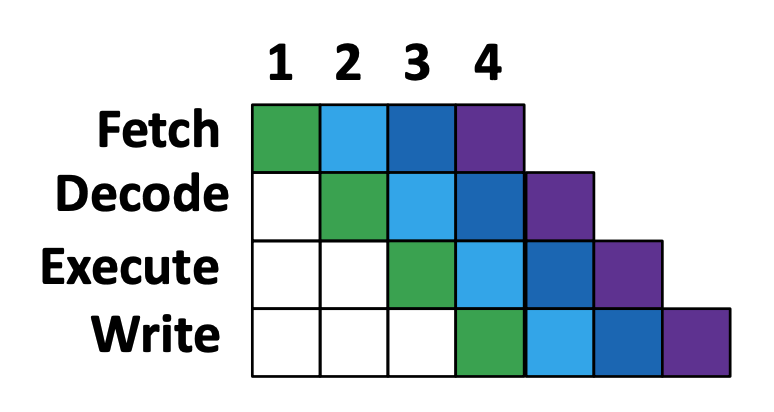
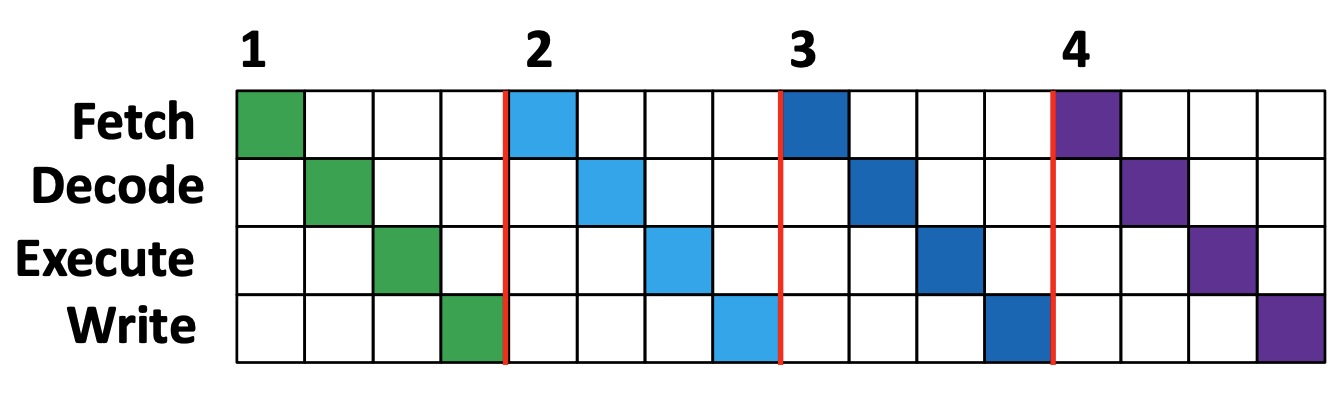
Excution Instruction in CPU
-
알아보기
Instruction Fetch (IF) : 다음에 실행할 명령어 레지스터 저장
Instruction Decode (ID) : 명령어를 해석
Excution (EX) : 해석한 결과로 명령어 실행
Write Back (WB) : 실행결과 메모리에 저장

이 과정 전체를 하나의 스레드라고 일컫습니다. 스레드를 이루는 각 단계는 CPU 클럭과 연동되어 한 클럭에 한 번씩 이루어집니다.
Super Scala 기법
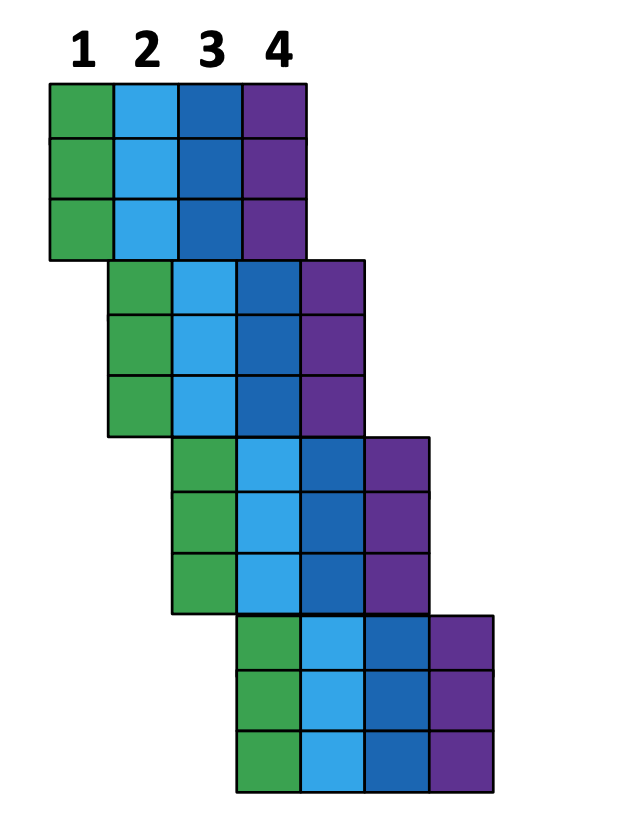
슈퍼스칼라는 CPU내에 파이프라인을 “여러 개 두어” 명령어를 동시에 실행하는 기술입니다. ILP를 최대한 적용하여 실행하면 CPU처리 속도가 빨라집니다. 파이프라인이 하나라면 클럭당 하나의 명령어만 완료할수 있었습니다.(IPC = 1) 이 값을 높이기 위해선 파이프라인을 여러 개 두어 명령어를 동시에 실행 시켜야 합니다.
Flops (FLoating point Operations Per Second)
플롭스는 컴퓨터의 성능을 수치로 나타낼 때 주로 사용되는 단위 입니다. 초당 부동 소수점 연산이라는 의미로 컴퓨터가 1초동안 수행할 수 있는 부동소수점 연산의 횟수를 기준으로 삼습니다.
개인용 컴퓨터의 CPU성능의 척도로는 클럭의 속도 단위인 헤르츠를 주로 사용하지만, 마이크로프로세서의 아키텍처의 구조에 따라 클럭당 연산 속도가 다르기 때문에 객관적인 성능을 비교할 때에는 플롭스를 사용합니다.
컴퓨터가 단위 시간(1s) 안에 처리할 수 있는 floationg point 연산을 하는지에 관한 지표입니다.
Flops 연산식
- 단일 프로세서에 대한 이론 성능 Flops 계산입니다.
- (프로세서의 clock 속도) X (cycle 당 명령 처리 수) X (FPU 개수) X (FPU당 연산 처리 방식에 따른 변수)
- ex) (1.3Ghz) X (1/inst./cycle) X (2FPU) = 2.6GFlops
- FPU : 부동소수점 연산 장치
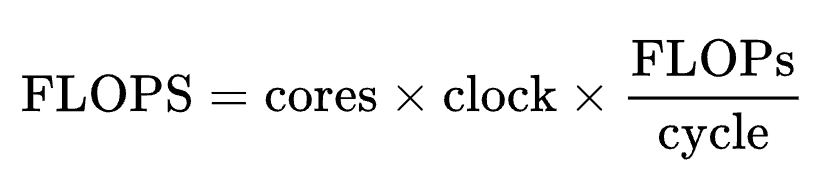
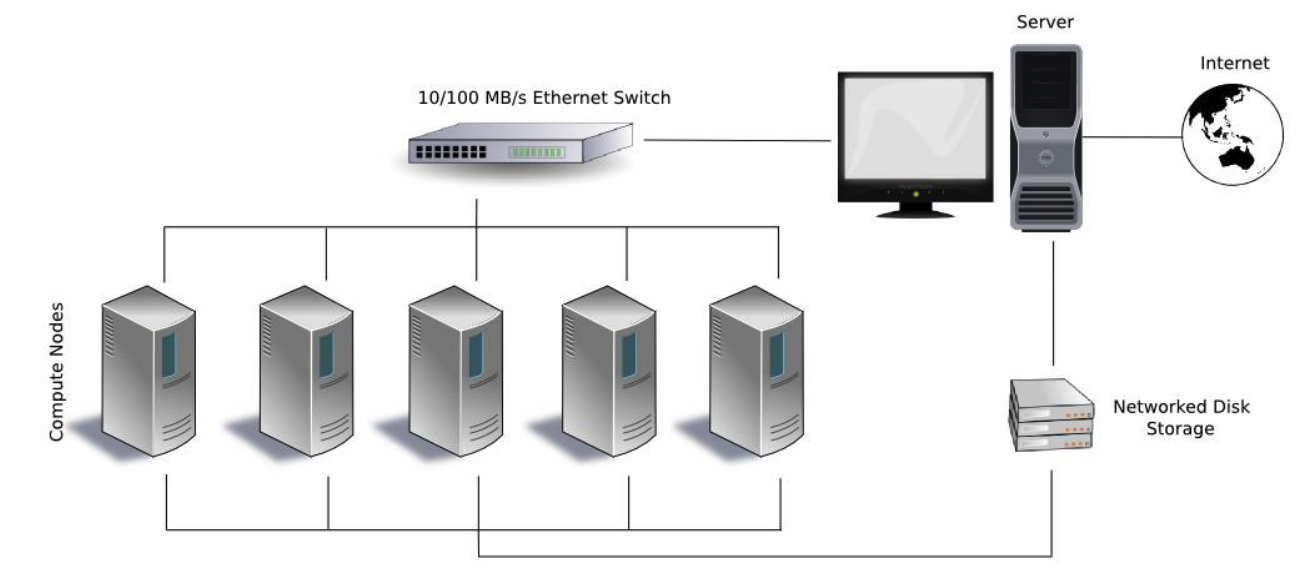
병렬 컴퓨터
현재의 HPC는 다수의 프로세서를 사용하는 병렬 컴퓨터입니다.
HPC를 분류하는 데는 여러 다른 방법이 존재합니다. (명확하게 분류할 수 있는 기준은 아직 없습니다.)
- 메모리 접근에 의한 구분 방법
- 공유 메모리 시스템
- OpenMP 병렬 프로그래밍 기법 사용
- 분산 메모리 시스템
- MPI 병렬 프로그래밍 기법
- 공유 분산 메모리 시스템 (하이브리드)
- MPI + OpenMP 병렬 프로그래밍 기법 사용
- 공유 메모리 시스템
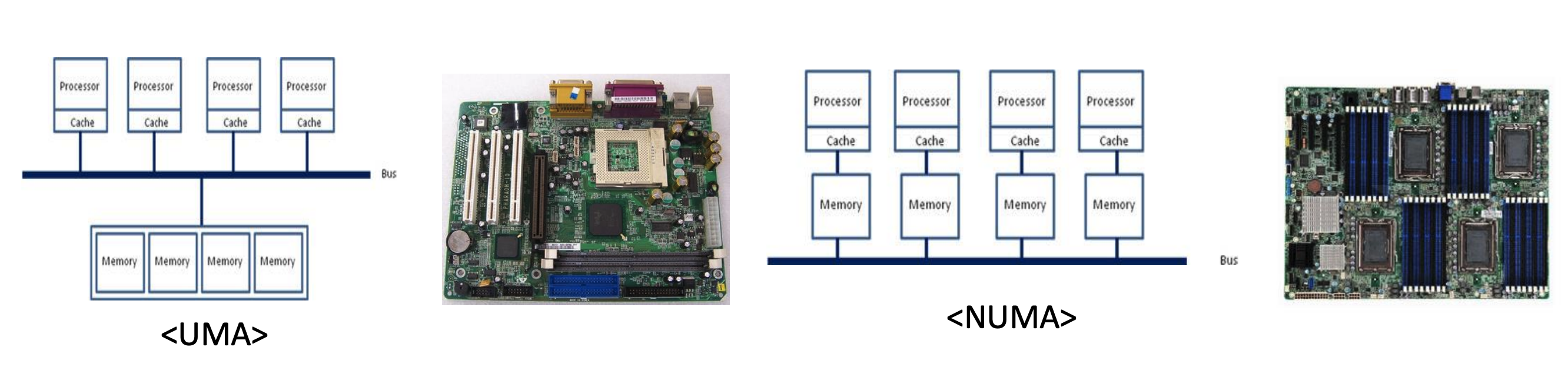
병렬 컴퓨터 구조
공유 메모리
분산 메모리
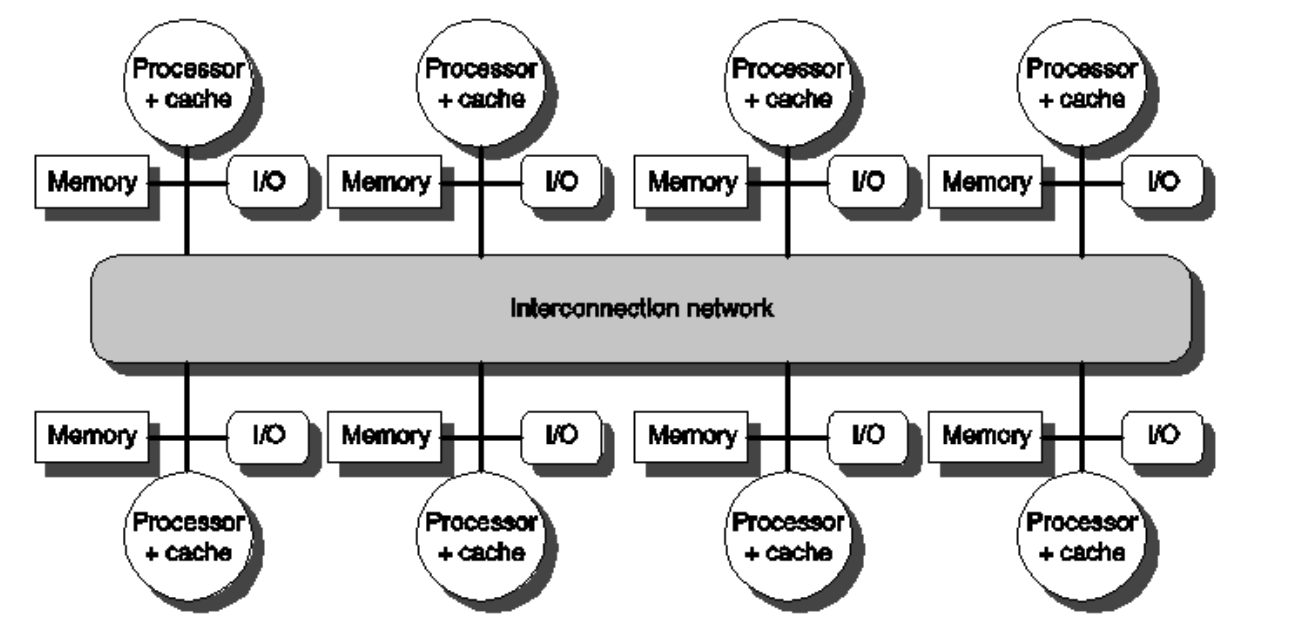
병렬 계산 모델
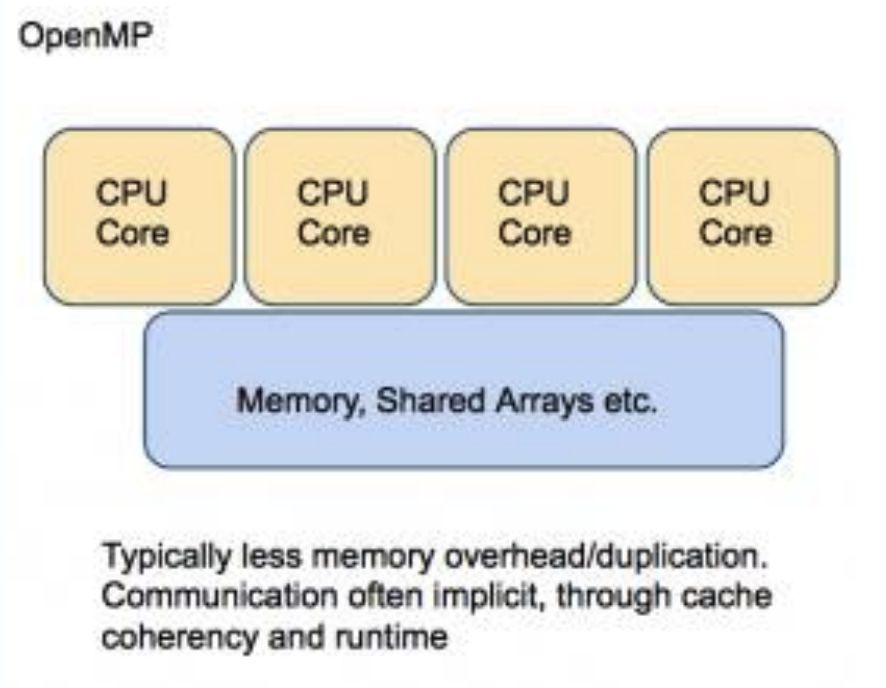
공유 메모리(Shared Memory)
- 전역 메모리 공간을 공유합니다.
- 멀티 코어를 가지고 있습니다.
- 각 코어들은 데이터를 효율적으로 교환 및 공유합니다.
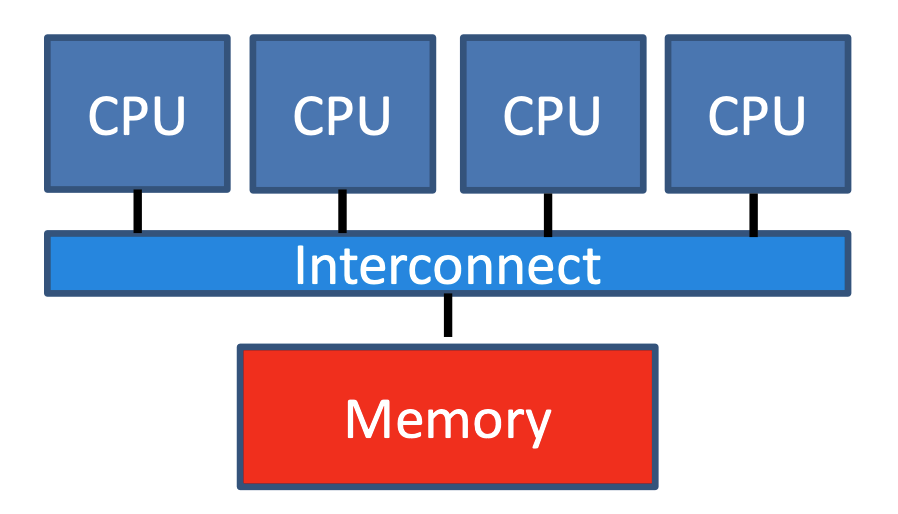
OpenMP (Open Multi Prossesor)
- 지시어는 프로세서에게 데이터를 어떻게 분배하고 프로세서들 끼리 어떻게 작동할지를 알려줍니다.
- 지시어는 순차코드에서 주석으로 인식됨
- 공유 메모리 아키텍처에서 수행됩니다.
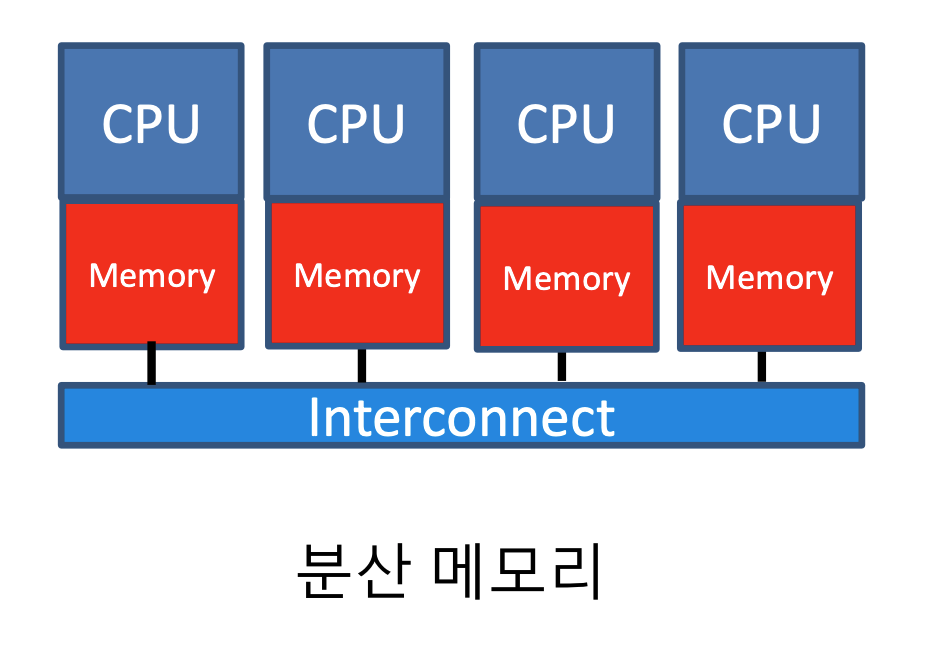
분산 메모리(Distribute Memory)
- 각 노드는 자신의 로컬 메모리를 사용합니다.
- 멀티 코어를 가진 노드들의 집합입니다.
- 메시지(message)를 통해 노드들과 코어들 사이의 통신을 수행합니다.
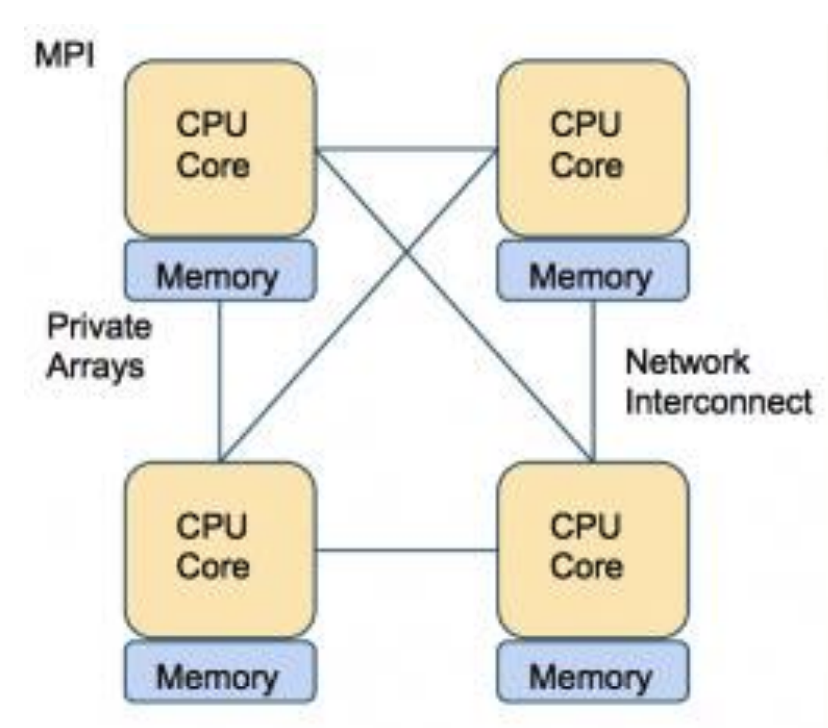
MPI (Message Passing Interface)
- 프로세스 사이에 데이터를 송수신 하기 위해서 메시지를 전달합니다.
- 각 프로세스는 자신만의 지역 변수들을 가집니다.
- 공유 메모리 혹은 분산 메모리 아키텍처에서 사용될 수 있습니다.
병렬 계산 S/W
컴파일러
- GCC, Inter Compiler, Cray Compiler
MPI(Message Passing Interface)
- 프로세서 사이의 통신과 데이터 교환을 위한 라이브러리
- 분산 메모리 시스템에서 사용됩니다.
- MPICH, OpenMPI
OpenMP
- 대표적인 공유 메모리 구조를 위한 프로그래밍 규약
- 컴파일러에 의해 지원
CUDA, OpenCL
- 가속기 및 멀티아키텍처를 위한 도구
수치 라이브러리
- BLAS, LAPACK, ScaLAPACK, Intel MKL, 등
- 일부는 스레드 또는 프로세스 병렬화를 지원합니다.
병렬 프로그래밍
프로세스와 스레드
프로세스
컴퓨터 시스템에 의해서 실행중인 프로그램
- task = process
- 분산 메모리 병렬 프로그램의 작업 할당 기준입니다.
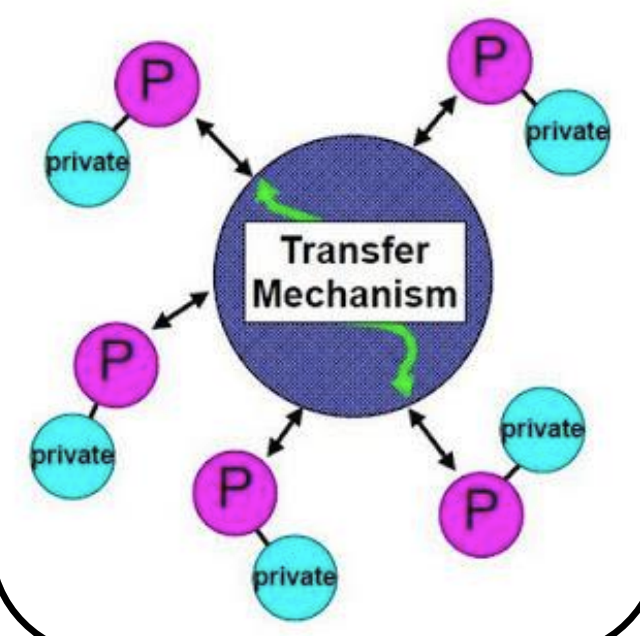
스레드
프로세스에서 실행의 개념만을 분리한 것
- 프로세스 = 실행단위(스레드) + 실행환경(공유자원)
- 하나의 프로세스는 하나 이상의 스레드를 가질수 있다.
- 공유 메모리 병렬 프로그램과 GPU 프로그래밍 모델의 작업 할당 기준

병렬 프로그래밍
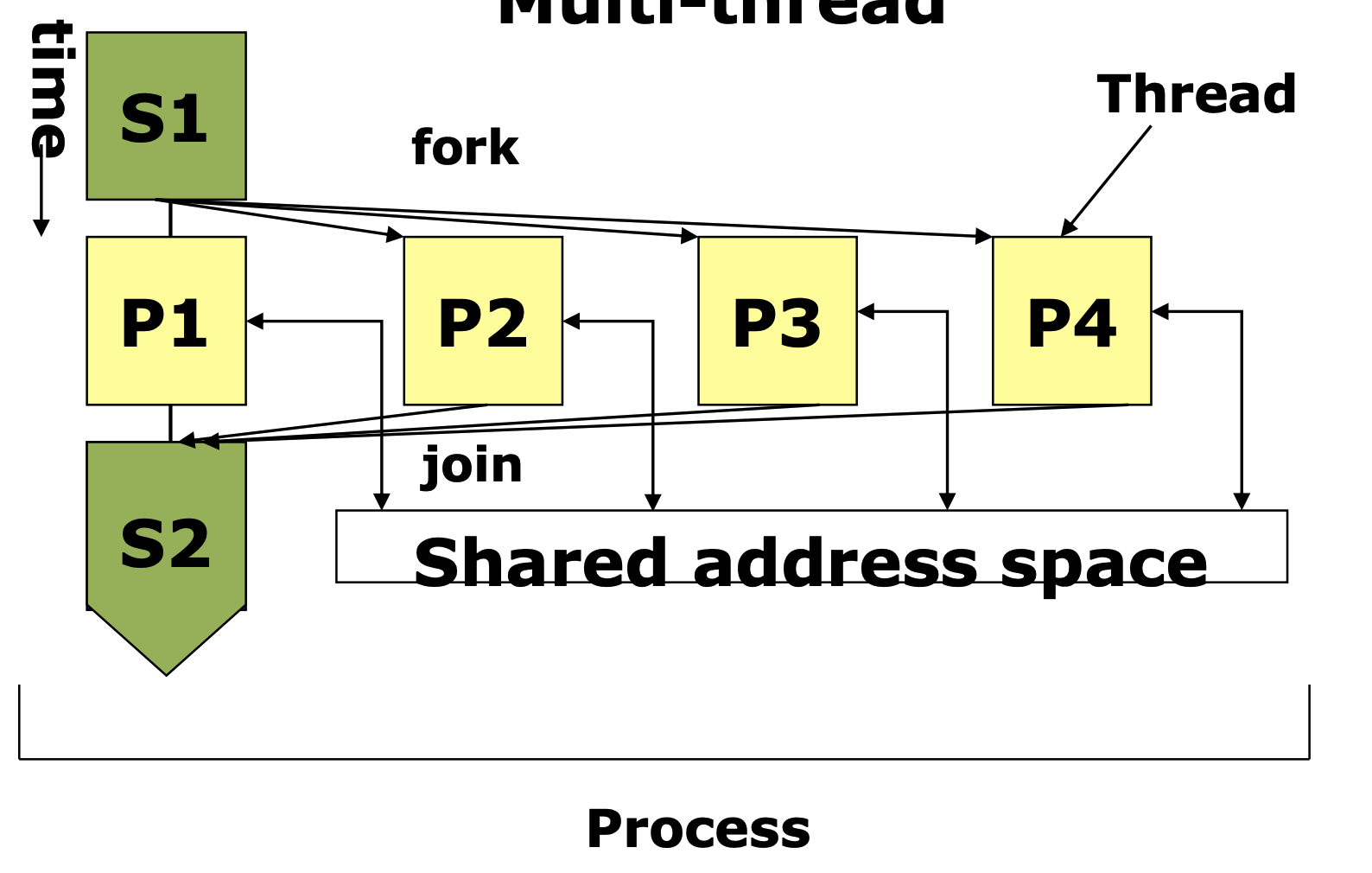
OpenMP
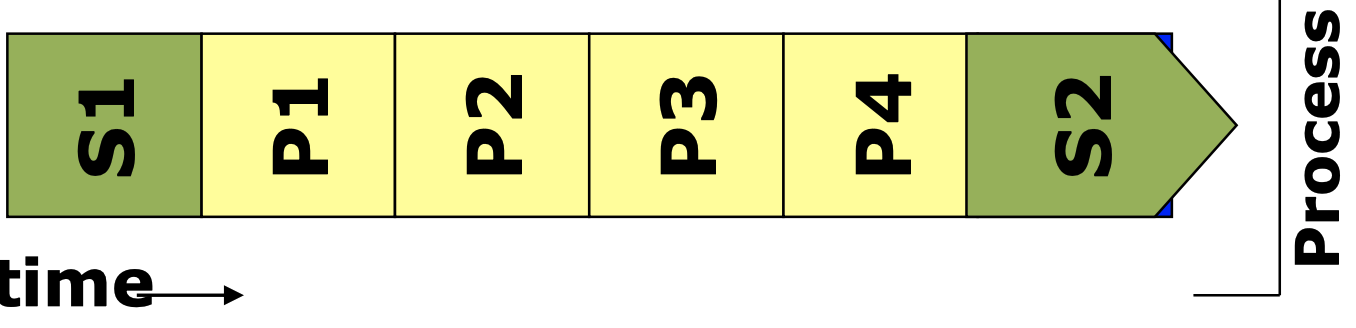
Single thread
Multi-thread
OpenMP 가 사용된 C프로그램을 컴파일하고 실행하는 스크립트
1 | |
MPI (Message Passing Interface)
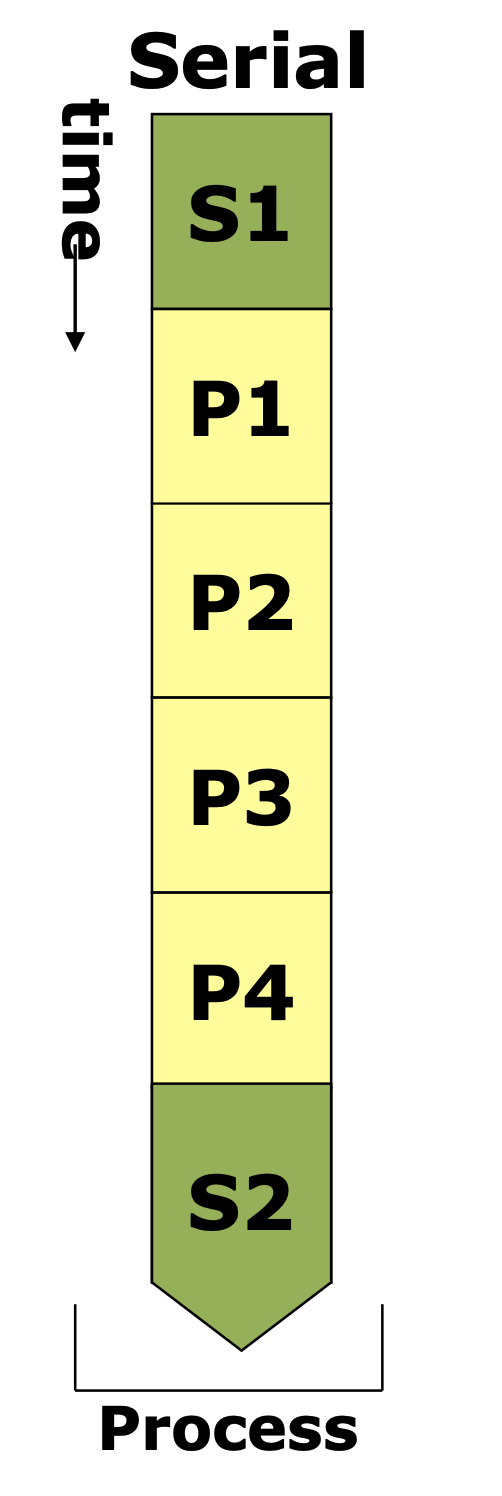
Serial
Message-passing
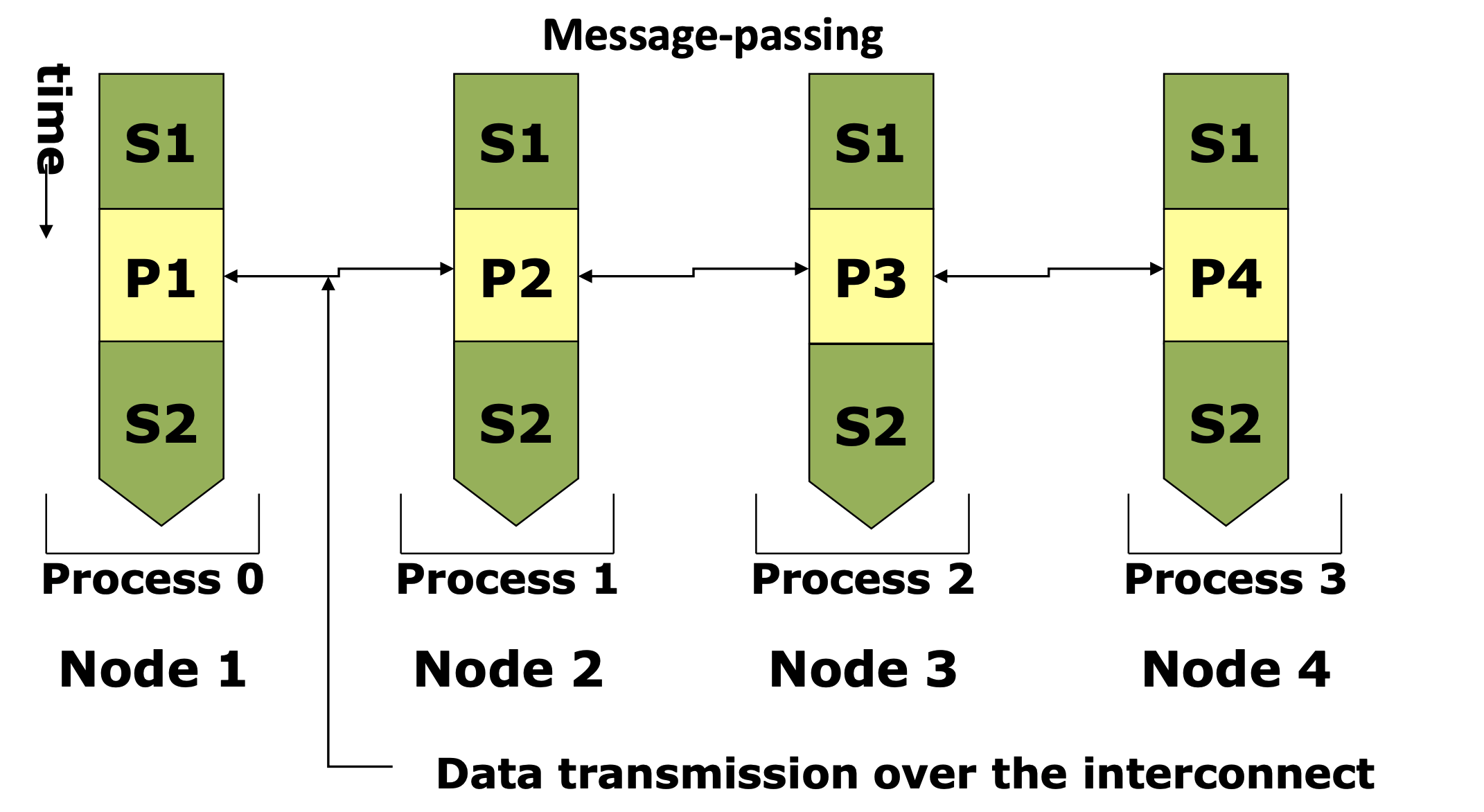
MPI(Message Passing Interface)가 사용된 C프로그램을 컴파일하고 실행하는 스크립트 입니다.
1 | |