모던 자바 인 액션
스트림 개념과 활용, 스트림 연산, 병렬 데이터 처리에 대해 학습합니다.
Chapter4 - 스트림
스트림이란
스트림(Stream)은 Java 8 API에 새로 추가된 기능이다. 스트림을 이용하면 선언형으로 컬렉션 데이터를 처리할 수 있다. 스트림을 이용하면 멀티스레드 코드를 구현하지 않아도 데이터를 투명하게 병렬로 처리할 수 있다.
1 | |
위 코드에서 lowCaloricDished의 가비지 변수를 사용했다. lowCaloricDished는 컨테이너 역할만 하는 중간 변수인데, 자바 8에서 이러한 세부 구현은 라이브러리 내에서 모두 처리한다.
아래는 위 코드를 스트림을 이용해서 처리한 코드다.
1 | |
스트림의 사용은 소프트웨어공학적으로 다음의 다양한 이득을 준다.
- 선언형으로 코드를 구현 가능 : 어떻게 동작을 구현할지 지정할 필요 없이
저칼로리의 요리만 선택하라같은 동작의 수행을 지정할 수 있다. 선언형 코드와 동작 파라미터화를 활용하면 변하는 요구사항에 쉽게 대응할 수 있다. - 여러 연산을 연결해서 데이터 처리 파이프라인 생성 가능 : filter, sorted, map, collect 같은 여러 빌딩 블록 연산을 연결해서 복잡한 데이터 처리 파이프라인을 만들 수 있다. 파이프라인으로 연결해도 가독성과 명확성이 유지되는데 이는 각 블록 연산의 아웃풋은 다음 연산의 input 값으로 연결되기 때문이다.
filter, sorted, map, collect 같은 연산은 고수준 빌딩 으로 이루어져 있어 특정 스레딩 모델에 제한되지 않고 자유롭게 어떤 상황에서든 사용할 수 있다.
결과적으로 데이터 처리 과정을 병렬화하면서 스레드와 락을 걱정할 필요가 없다.
고수준 빌딩 블록으로 인해 특정 스레딩 모델에 제한되지 않는다는 말은
filter,map,collect등과 같은 연산들이 특정 스레딩 모델(예: 단일 스레드, 멀티 스레드, 병렬 처리 등)에 의존하지 않고, 어떤 스레딩 환경에서도 동일한 방식으로 동작하며 추상화된 구조를 제공한다는 뜻이다.
filter,map,collect등의 연산은 내부적으로 구현된 추상화를 통해 데이터 처리 방식을 캡슐화 하기 때문에 프로그래머는 데이터 처리 로직에만 집중하면 되고, 연산이 어떤 스레딩 모델이나 병렬 처리 메커니즘을 사용하는지 걱정하지 않아도 된다.
스트림 API는 매우 비싼 연산이다.
스트림의 설계와 실행 과정에서 발생하는 여러 오버헤드와 연관이 존재한다. 스트림이 고수준 추상화를 제공하면서도 내부적으로 복잡한 동작을 수행하기 때문이다. 자세한 것은 뒤에서 알아본다.
Java 8의 스트림 API 특징은 다음과 요약할 수 있다.
- 선언형 : 간결하고 가독성이 좋다.
- 조립할 수 있음 : 유연성이 좋아진다.
- 병렬화 : 성능이 좋아진다.
스트림 시작하기
Java 8 컬렉션에는 스트림을 반환하는 stream 메서드가 추가됐다. 숫자 범위나 I/O 자원에서 스트림 요소를 만드는 등 stream 메서드 이외에도 다양한 방법으로 스트림을 얻을 수 있다.
스트림이란 데이터 처리 연산을 지원하도록 소스에서 추출된 연속된 요소로 정의할 수 있다.
- 연속된 요소 : 컬렉션은 시간과 공간의 복잡성과 관련된 요소 저장 및 접근 연산이 주를 이루지만, 스트림은 표현 계산식이 주를 이룬다. 컬렉션의 주제는 데이터고 스트림의 주제는 계산이다.
- 소스 : 스트림은 컬렉션, 배열, I/O 자원등의 데이터 제공 소스로부터 데이터를 소비한다. 정렬된 컬렉션으로 스트림을 생성하면 정렬이 그대로 유지된다. 즉 리스트로 스트림을 만들면 스트림의 요소는 리스트의 요소와 같은 순서를 유지한다.
- 데이터 처리 연산 : 함수형 프로그래밍 언어에서 일반적으로 지원하는 연산과 데이터베이스와 비슷한 연산을 지원한다. 예를 들어
filter,map,reduce,find,match,sort등으로 데이터를 조작할 수 있다. 스트림 연산은 순차적으로 또는 병렬로 실행할 수 있다. - 파이프라이닝 : 스트림 자신을 반환한다. 그 덕에
Lazyness,short-circuting같은 최적화도 얻을 수 있다. 연산 파이프라인은SQL 과 비슷하다. - 내부 반복 : 반복자를 이용해서 명시적으로 반복하는 컬렉션과 달리 스트림은 내부 반복을 지원한다.
Lazyness(게으름..)이란 스트림의 중간연산은 게으르게 평가된다는 뜻이다. 결과를 즉시 계산하지 않고, 최종 연산이 호출될 대 필요한 데이터에 대해서만 실행된다. 이는 불필요한 연산을 피할 수 있는 장점이 있다. Short-circuiting(쇼트서킷)은 파이프라인에서 모든 데이터를 처리하지 않아도 결과를 확정할 수 있을 때, 남은 데이터 처리를 건너뛰는 동작을 말한다. ex) limit()
스트림과 컬렉션
자바의 기존 컬렉션과 새로운 트림 모두 연속된 요소 형식의 값을 저장하는 자료구조 인터페이스를 제공한다.
여기서의
연속된이란 순차적으로 값에 접근한다는 것을 의미한다.
데이터를 언제 계산하느냐가 컬렉션과 스트림의 가장 큰 차이다. 컬렉션은 자료구조가 포함하는 모든 값을 메모리에 저장하고, 컬렉션은 요청할 때만 요소를 계산하는 고정된 자료구조다.
스트림은 생상자와 소비자 관계를 형성하며 게으르게 만들어지는 컬렉션과 같다. 사용자가 데이터를 요청할 때만 값을 계산한다.
반면 컬렉션은 적극적으로 생성된다.
딱 한 번만 탐색할 수 있다.
탐색된 스트림의 요소는 소비된다. 다시 탐색하기 위해선 초기 데이터 소스에서 새로운 스트림을 생성해야 한다.
외부 반복과 내부 반복
외부 반복 : 사용자가 직접 요소를 반복
내부 반복 : 반복을 알아서 처리하고 결과 스트림 값을 어딘가에 저장해주는 작업
스트림 연산
중간 연산 : 연결할 수 있는 스트림 연산
최종 연산 : 스트림을 닫는 연산

중간 연산
filter나 sorted 같은 중간 연산들은 다른 스트림을 반환한다. 중간 연산의 중요한 특징은 단말 연산을 스트림 파이프라인에 실행하기 전까지는 아무 연산도 수행하지 않는다는 것이다.
중간 연산은 스트림 파이프라인에서 데이터를 처리하는 방식을 정의만 할 뿐, 실제 데이터 처리는 단말 연산이 호출될 때 이루어진다. 이는 게으른 평가(Lazy Evaluation)라는 개념과 연결된다.
최종 연산
스트림 파이프라인에서 결과를 도출한다. List, Integer, void 등 스트림 이외의 결과가 반환된다.
스트림 이용하기
스트림 이용 과정은 아래 세 가지로 요약할 수 있다.
- 질의를 수행할 데이터 소스
- 스트림 파이프라인을 구성할 중간 연산 연결
- 스트림 파이프라인을 실행하고 결과를 만들 최종 연산
| 연산 | 형식 | 반환 형식 | 연산의 인수 | 함수 디스크립터 |
|---|---|---|---|---|
filter |
중간 연산 | Stream |
Predicate<T> |
T -> boolean |
map |
중간 연산 | Stream |
Function<T, R> |
T -> R |
sorted |
중간 연산 | Stream |
Comparator<T> |
(T, T) -> int |
limit |
중간 연산 | Stream |
- | |
distinct |
중간 연산 | Stream |
- |
| 연산 | 형식 | 반환 형식 | 목적 |
|---|---|---|---|
forEach |
최종 연산 | void | 스트림의 각 요소를 소비하면서 람다를 적용한다. |
count |
최종 연산 | long (generic) | 스트림의 요소 개수를 반환한다. |
collect |
최종 연산 | 스트림을 리듀스해서 리스트, 맵, 정수 형식의 컬렉션을 만든다. |
Chapter5 - 스트림 활용
스트림은 데이터를 어떻게 처리할지 내부적으로 관리하기 때문에 편리하게 데이터 관련 작업을 할 수 있다. 따라서 스트림 API는 내부적으로 다양한 최적화가 이루어질 수 있다. 더불어 스트림 API는 내부 반복 뿐 아니라 코드를 병렬로 실행할지 여부도 결정할 수 있다.
필터링
스트림의 요소를 선택하는 방법에 대해 기술한다.
Predicate로 필터링
filter 메소드는 predicate(boolean을 반환하는 함수)를 인수로 받아서 predicate와 일치하는 모든 요소를 포함하는 스트림을 반환한다.
1 | |
고유 요소를 필터링
스트림은 고유 요소를 필터링하는 distinct 메서드를 지원한다. 고유 여부 판단은 스트림에서 만든
객체의 hashcode, equals로 결정된다.
1 | |
스트림 슬라이싱
스트림의 요소를 선택하거나 스킵하는 방법이 존재한다.
Java 9는 스트림의 요소를 효과적으로 선택할 수 있도록 takeWhile, dropWhile 두 가지 새로운 메서드를 지원한다.
takeWhile 활용하기
정렬된 컬렉션이 존재할때 특정 조건에 만족하는 요소들을 선택하고 싶을때 takeWhile을 사용하면 된다.
filter연산을 사용해도 되지만 이는 모든 요소를 탐색하는 비용이 존재한다.
1 | |
dropWhile 활용하기
나머지 요소를 선택하려면 dropWhile을 사용하여 처리할 수 있다. dropWhile은 predicate가 처음으로 거짓이 되는 지점에서 작업을 중단하고 발견된 요소를 버린다. 그리고 남은 요소를 반환한다.
1 | |
스트림 축소
스트림은 주어진 값 이하의 크기를 갖는 새로운 스트림을 반환하는 limit(n) 메서드를 지원한다. 스트림이 정렬되어 있다면
최대 요소 n개를 반환할 수 있다.
1 | |
요소 건너뛰기
스트림은 처음 n개 요소를 제외한 스트림을 반환하는 skip(n) 메서드를 지원한다. limit(n)과 skip(n)은 상호 보완적인 연산을 수행한다.
1 | |
매핑
스트림 API의 map과 flatMap 메서드는 특정 데이터를 선택하는 기능을 제공한다.
스트림의 각 요소에 함수 적용하기
map연산의 인수는 함수이다. 함수는 각 요소에 적용되며 함수를 적용한 결과가 새로운 요소로 매핑된다.
- 변환에 가까운 매핑의 개념
1 | |
flatMap 사용
flatMap 메서드는 스트림의 각 값을 다른 스트림으로 만든 다음 모든 스트림을 하나의 스트림으로 연결한다.
1 | |
검색과 매칭
스트림 API는 allMatch, anyMatch, noneMatch, findFirst, findAny 등 다양한 유틸리티 메서드를 제공한다.
적어도 한 요소와 일치하는지 확인
anyMatch 메서드를 사용하면 주어진 스트림에서 적어도 한 요소와 일치하는지 확인할 수 있다.
- anyMatch는 boolean을 반환하는 최종 연산이다.
1 | |
모든 요소와 일치하는지 검사
allMatch 메서드는 anyMatch와 달리 스트림의 모든 요소가 주어진 프레디케이트와 일치하는지 검사한다.
1 | |
NONEMATCH
noneMatch는 allMatch와 반대 연산을 수행한다.
1 | |
요소 검색
findAny 메서드는 현재 스트림에서 임의의 요소를 반환한다.
1 | |
리듀싱
reduce() 스트림 요소를 누적하거나, 집계하여 단일 결과값을 생성하는 연산
BinaryOperator - 두 요소를 조합해서 새로운 값을 만드는 연산
- 리듀싱 연산은 초기값, 누적 함수, 병합 함수로 구성
초기값이 있는 경우
1 | |
초기값이 없는 경우
1 | |
병렬 연산을 위한 병합 함수 사용
1 | |
reduce 메서드의 장점과 병렬화
- reduce를 이용하면 내부 반복이 추상화되면서 내부 구현에서 병렬로
reduce를 실행 - 스트림은 내부적으로 포크/조인 프레임워크(fork/join framework)를 통해 이를 처리
스트림 연산 : 상태 없음과 상태 있음
스트림 연산은 데이터 처리를 수행하는 방식에 따라 상태 없는 연산과 상태 있는 연산으로 나뉜다.
이는 스트림의 요소를 처리하는 데 있어 연산의 이전 요소 상태를 참조하는지 여부에 따라 구분된다.
- 상태 없는 연산 (Stateless Operations)
- 각 요소를 독립적으로 처리하며, 이전 요소의 상태에 의존하지 않음
- 스트림의 크기와 관계없이 효율적으로 동작
- 병렬 처리와 최적화에 유리
- 상태 있는 연산 (Stateful Operations)
- 처리 중 일부 연산이 이전 요소의 상태를 필요로 하거나 전체 스트림을 참조해야 함
- 스트림의 크기에 따라 성능이 영향을 받을 수 있음
- 병렬 처리 시 더 많은 리소스를 사용하며 복잡도 증가 가능성 존재
숫자형 스트림
- 스트림 API는 숫자 스트림을 효율적으로 처리할 수 있도록 기본형 특화 스트림(primitive stream specialization)을 제공
기본형 특화 스트림
- 기본형 특화 스트림(IntStream, LongStream, DoubleStream)은 Java Stream API에서 성능 최적화를 위해 기본 데이터 타입(int, long, double)을 처리하도록 설계된 스트림
객체 스트림으로 복원하기
- boxed메서드를 이용하면 특화 스트림을 일반 스트림으로 변환 가능
1 | |
숫자 범위
- range와 rangeClosed 메서드를 사용하여 특정 숫자의 범위를 이용할 수 있음
- range: 시작값 포함, 끝값 미포함.
- rangeClosed: 시작값과 끝값 모두 포함.
1 | |
스트림 만들기
컬렉션에서 생성
stream()또는parallelStream()메서드를 사용.
1 | |
배열에서 생성
Arrays.stream()메서드를 사용
1 | |
정적 팩토리 메서드
Stream.of()를 사용
1 | |
숫자 범위로 생성
1 | |
Builder 사용하기
1 | |
무한 스트림 생성
Stream.generate()또는Stream.iterate()를 사용하여 무한히 생성
1 | |
파일에서 생성
- Files.lines()로 파일의 각 줄을 스트림으로 읽음
1 | |
Chapter6 - 스트림으로 데이터 수집
컬렉터란
Collector 인터페이스 구현은 스트림 요소를 어떤 식으로 도출할지 지정한다.
스트림의 요소를 수집하거나 변환하는 방법을 정의한 인터페이스로,
java.util.stream.Collectors 유틸리티 클래스를 통해 자주 사용되는 컬렉터 구현체들을 제공한다.
- 스트림 결과를 다양한 방식으로 수집
스트림의 데이터를 컬렉터를 사용해 리스트(List), 셋(Set), 맵(Map) 등 다양한 컬렉션으로 변환하거나, 합계, 평균, 문자열 결합 등으로 처리할 수 있다.
- 프로그래밍 모델
컬렉터는 Collector 인터페이스를 구현하며, 데이터 수집 과정에 필요한 세 가지 함수를 정의한다.
- supplier: 누적할 객체 생성
- accumulator: 데이터를 누적
- combiner: 병렬 스트림의 경우 두 부분 결과를 병합
리듀싱과 요약
데이터 그룹화 및 분할
- groupingBy(): 데이터를 특정 기준으로 그룹화
- partitioningBy(): 데이터를 참/거짓 조건에 따라 분할
요약 및 통계
- counting(): 스트림의 요소 수 계산
- summarizingInt(), summarizingDouble(), summarizingLong(): 통계 요약
- maxBy(), minBy(): 최대값, 최소값 계산
결과 조합
- joining(): 문자열로 요소 결합
- toList(), toSet(), toMap(): 결과를 컬렉션으로 변환
커스텀 컬렉터
필요에 따라 Collector 인터페이스를 직접 구현해 원하는 수집 과정을 정의할 수도 있다.
Collector 인터페이스
Collector 인터페이스는 리듀싱 연산을 어떻게 구현할지 제공하는 메서드 집합으로 구성된다. Collector 인터페이스를 직접 구현해서 더 효율적으로 문제를 해결하는 컬렉터를 만드는 방법을 살펴보자.
스트림의 데이터를 모아서 원하는 결과를 만드는 방법을 정의하는 도구이자 스트림에서 데이터를 모아 최종 결과를 만드는 설계도
Supplier<A> supplier()- 누적자(Accumulator) 객체를 초기화하는 공급자 함수를 반환합니다.
- 예: 빈 컬렉션(List, Set 등)을 생성.
BiConsumer<A, T> accumulator()- 누적자 객체(A)에 스트림 요소(T)를 추가하는 로직을 정의한 누적 함수를 반환합니다.
- 예: 리스트에 요소를 추가하거나 값을 합산.
BinaryOperator<A> combiner()- 병렬 처리에서 여러 누적자 객체를 병합하는 결합 함수를 반환합니다.
- 병렬 스트림에서 여러 스레드가 생성한 결과를 하나로 합칠 때 사용.
Function<A, R> finisher()- 최종 결과로 변환하는 변환 함수를 반환합니다.
- 예: 누적된 데이터를 원하는 데이터 타입으로 변환.
Set<Characteristics> characteristics()
컬렉터의 특성을 정의, 다음과 같은 특성을 가질 수 있음- UNORDERED: 결과의 순서가 스트림 요소의 순서에 의존하지 않음.
- CONCURRENT: 다중 스레드 환경에서 병렬로 누적할 수 있음.
- IDENTITY_FINISH: 변환 함수(finisher())가 생략 가능하며 누적자가 결과 타입과 동일함.
Collector 인터페이스 동작 과정 요약
- 공급자(Supplier): 초기 상태 생성 (예: 빈 리스트, 맵, 합계 변수 등)
- 누적(Accumulator): 스트림의 각 요소를 누적자에 추가
- 결합(Combiner): 병렬 처리를 위한 병합 로직
- 마무리(Finisher): 최종 변환 또는 반환
- 특성(Characteristics): 병렬 가능 여부, 순서 보장 여부 등 지정
Collector 예제
1 | |
Chapter7 - 병렬 데이터 처리와 성능
Java7 이전의 컬렉션 병렬처리의 단점은 아래와 같다.
- 데이터를 서브파트로 분할해야 한다.
- 서브파트를 각각 스레드에 할당하고, 공유자원에 대한 레이스 컨디션을 고려해야 한다.
- 부분 결과를 병합해야 한다.
Java7 포크/조인(Fork/Join) 프레임워크기능을 제공하여 더 쉽게 병렬화를 수행한다.
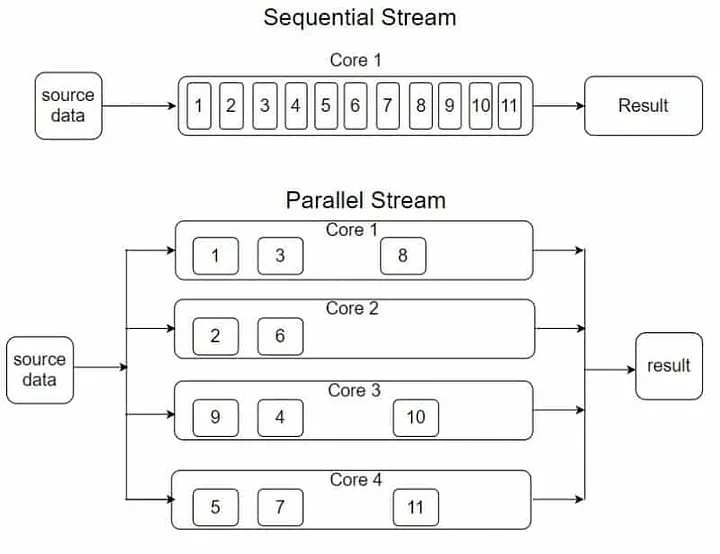
병렬 스트림
parallelStream을 사용하여 병렬 스트림을 생성할 수 있으며, 병렬 스트림이란
각 스레드에서 처리할 수 있도록 스트림 요소를 여러 청크로 분할한 스트림 이다.
 [출처-https://dip-mazumder.medium.com/processing-a-large-log-file-of-10gb-using-java-parallel-streams-693bb98828aa]
[출처-https://dip-mazumder.medium.com/processing-a-large-log-file-of-10gb-using-java-parallel-streams-693bb98828aa]
- 병렬 스트림은 스트림을
Chunk단위로분할 한다. - 기기의 프로세서 코어는 각
Chunk단위를 병렬로 수행한다.
병렬 스트림 스레드 풀 설정
- 병렬 스트림은 기본적으로 ForkJoinPool.commonPool을 사용한다.
- 풀의 크기는 Runtime.getRuntime().availableProcessors() - 1로 설정된다.
- 특별한 이유가 없다면
ForkJoinPool기본값을 그대로 사용할 것을 권장한다.
스트림 성능 측정을 통한 병렬 처리의 함정 알아보기
- 병렬 처리는 순차, 반복 형식에 비해 성능이 좋아질 것 이라고 가정하고 시작한다.
- java21, JMH, MAVEN 으로 구성하였다.
1 | |
컴파일 후 아래 명령어로 실행
1 | |
결과
- For문(순차 스트림 약 18배 성능) > 순차 스트림 > 병렬 스트림
이전 연산의 결과에 따라 다음 함수의 입력이 달라지기 때문에 iterate 연산을 청크로 분할하기 어렵다. (본질적인으로 순차적)
스트림이 병렬로 처리되도록 지시했지만 각 스레드에서 합계가 처리되었지만, 순차처리 방식과 다른 점이 없으므로 스레드 할당 오버헤드만 증가하였다.
병렬 프로그래밍의 오용하는 것을 경계하라, 병렬 프로그래밍은 조화와 절제를 잃으면, 속도의 유혹 속에서 본질을 잃고 혼란만 가중시키는 칼날이 된다.
병렬 스트림 효과적으로 사용하기
- 확신이 서지 않을때는 성능을 측정하여 확인
- 박싱을 주의해야 한다. 오토박싱, 언박싱은 성능을 저하시키는 요소
- 기본형 특화 스트림(IntStream, LongStream, DoubleStream)을 사용
- 요소 순서에 의존하는 연산은 병렬 스트림의 비싼 비용을 치룬다.
- 순서가 상관없다면 비정렬된 스트림에 limit를 호출하는 테크닉을 사용
- 소량의 데이터에서는 병렬 스트림이 도움 되지 않는다.
- 스트림을 구성하는 자료구조를 확인하라.
- LinkedList는 요소 전체 탐색, ArrayList는 탐색없이 분할 가능
- 최종 연산의 병합 과정 비용 살펴보기
| 스트림 소스 | 분해성 설명 |
|---|---|
| 배열 (Array) | 내부적으로 배열의 인덱스를 기준으로 분할되어 병렬 처리에 적합하다. |
| 리스트 (List) | ArrayList는 배열 기반이라 분해성이 좋다. 하지만 LinkedList는 분해 과정에서 순차 접근이 필요하므로 분해성이 떨어진다. |
| 집합 (Set) | HashSet은 요소를 효율적으로 분할할 수 있지만, TreeSet은 정렬 구조 때문에 분할 시 성능이 낮아질 수 있다. |
| 맵 (Map) | HashMap은 키-값 쌍을 분리하여 쉽게 병렬 처리할 수 있어 분해성이 좋다. TreeMap은 정렬된 구조로 인해 분해성이 낮다. |
| 파일 I/O | 파일 데이터는 스트림으로 읽을 때 분할 처리가 가능하다. 그러나 스트림 자체가 순차적으로 작동하므로 대규모 데이터는 특별한 분할 전략이 필요하다. |
| Range (범위) | 숫자 범위는 분할하기 용이하다. 시작과 끝 값을 기준으로 하위 범위로 쉽게 나눌 수 있어 높은 분해성을 가진다. |
| Queue (큐) | ConcurrentLinkedQueue와 같은 병렬 처리 지원 큐는 분해성이 좋다. 그러나 BlockingQueue는 동기화 제약으로 인해 분해성이 떨어진다. |
| 문자열 (String) | 문자열은 요소(문자) 단위로 분할 가능하지만, 문자열의 길이에 따라 성능이 영향을 받을 수 있다. 긴 문자열은 병렬 처리로 효과를 볼 수 있다. |
| 데이터베이스 쿼리 | 쿼리 결과는 기본적으로 순차 처리된다. 쿼리 자체를 범위 또는 조건별로 나누어 요청하면 높은 분해성을 얻을 수 있다. |
| Custom Stream | 사용자 정의 스트림의 분해성은 소스의 구조와 스트림 분할 전략에 따라 다르다. 병렬 처리를 염두에 둔 설계를 통해 분해성을 높일 수 있다. |
포크/조인 프레임워크
병렬 프레임워크로, 작업을 재귀적으로 나누어(Fork) 분할한 다음 각 서브태스크의 결과를 합쳐서(Join) 결과를 만든다.
- ForkJoinPool
- 작업을 효율적으로 관리하는 스레드 풀
- 작업 훔치기(Work-Stealing) 알고리즘을 사용하여 CPU 자원을 최대한 활용
- ForkJoinTask : Fork/Join 프레임워크에서 실행되는 작업의 기본 단위로 두 가지로 구분됨
- RecursiveTask: 결과를 반환하는 작업.
- RecursiveAction: 결과를 반환하지 않는 작업.
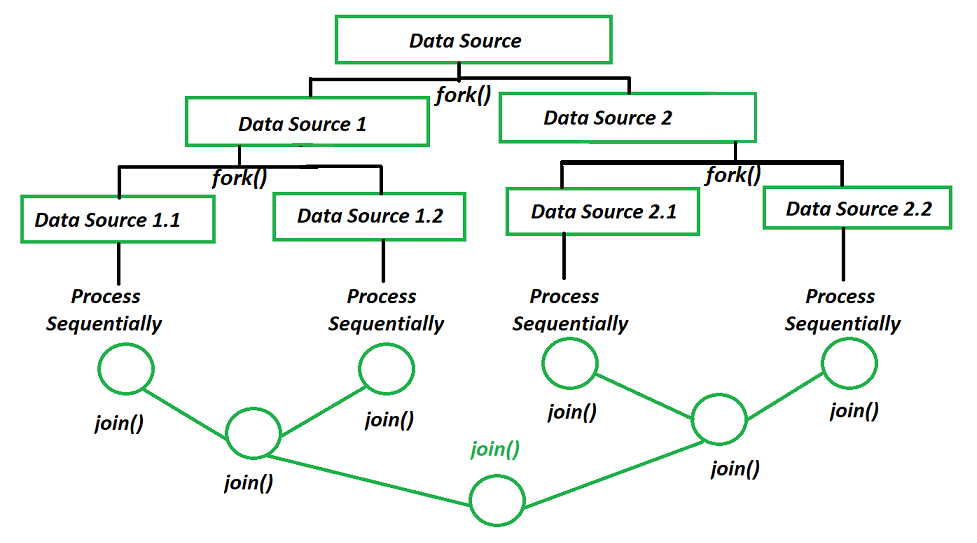
포크/조인 프레임워크를 제대로 사용하는 방법
- 두 서브태스크가 모두 시작된 다음에 join을 호출해야 한다. (서브태스크에서 join 메서드를 호출하면 결과가 준비될 때까지 블록)
- RecursiveTask 내에서는 ForkJoinPool의 invoke 메서드를 사용하지 말아야 한다. 대신 compute나 fork 메서드를 호출하자
- 왼쪽 작업과 오른쪽 모두에 fork메서드를 사용하는 것대신, 한쪽 작업에 compute를 호출하는 것이 스레드를 재사용할 수 있다.
- 디버깅이 어렵다는 점을 고려하자.
- 각 서브태스크의 실행시간은 새로운 태스크를 포킹하는 데 드는 시간보다 길어야 한다.
작업 훔치기 (Work-Stealing) 알고리즘
Fork/Join Framework에서 사용되는 핵심 개념으로, 유휴 상태의 스레드가 다른 스레드의 작업을 훔쳐 실행하는 방식
이 알고리즘은 스레드의 작업 불균형 문제를 해결하고, CPU 자원을 효율적으로 활용하는 데 목적이 있다.
Spliterator 인터페이스
Spliterator는 Java 8에서 추가된 인터페이스로, Java의 Stream API와 함께 사용할 수 있도록 설계되었다. Spliterator는 컬렉션 요소를 효율적으로 탐색하고 분할할 수 있는 기능을 제공한다.
주요특징
- 병렬 처리 지원
- 순차 및 분할 탐색 가능
- 컬렉션 불변성
1 | |
tryAdvance: 요소 순차 탐색, 남은 요소 존재시 action 수행 true 반환, 없다면 false 반환trySplit: Spliterator를 분할하여 새 Spliterator를 반환estimateSize: 남은 요소의 예상 크기를 반환 (반환값이 정확하지 않을 수도 있지만, 병렬 처리의 작업 크기를 예측하는 데 사용)characteristics: Spliterator의 특성을 나타내는 비트 집합을 반환ORDERED: 요소가 순서를 유지함.DISTINCT: 요소가 고유함.SORTED: 요소가 정렬됨.SIZED: 요소의 크기가 고정됨.IMMUTABLE: 데이터 소스가 변경되지 않음.